许多开发者在接触 Telegram API 时,最直观的感受就是其极高的响应速度。作为一款日活过亿的即时通讯工具,Telegram 在多语言开发方面的架构设计堪称典范。它并非简单地通过翻译文件堆叠功能,而是通过高效的底层逻辑,实现了全球化用户的无缝交互体验。
基于 MTProto 的底层协议优势
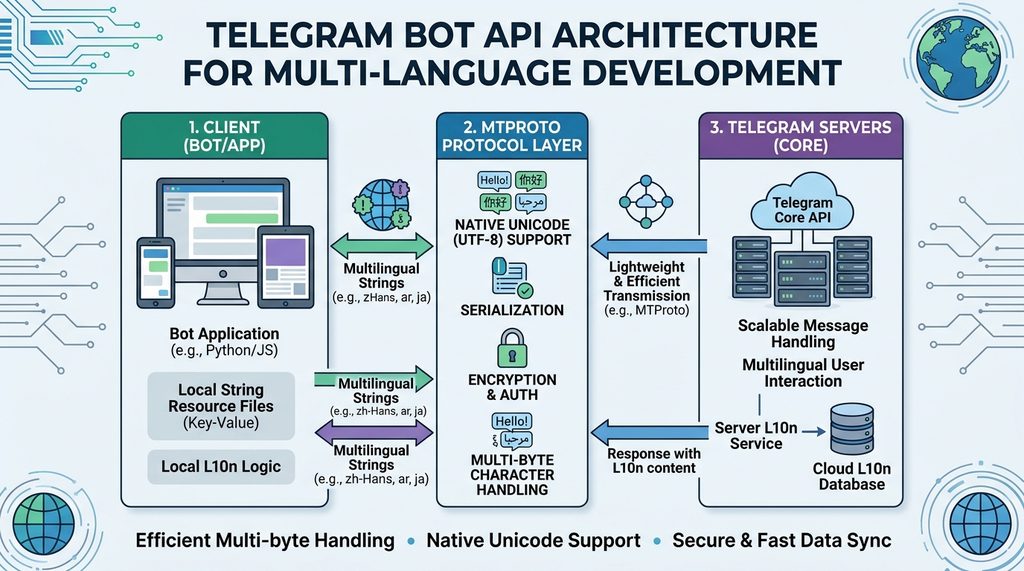
Telegram 的核心在于其自研的 MTProto 协议。相比于传统的 HTTP REST API,这种协议在处理多语言字符编码时更加轻量且高效。在多语言开发过程中,尤其是处理非拉丁语系(如中、日、韩、阿)的字符时,MTProto 能够大幅减少传输负载。
开发者在调用 Telegram Bot API 时,会发现其对 Unicode 的原生支持非常稳健。无论你在消息中嵌入哪种语言的特殊符号或多字节字符,系统都能确保数据在毫秒级内完成序列化与反序列化,不会出现乱码或解析延迟。
模块化的字符串管理策略
Telegram 并没有将所有文本硬编码在程序中,而是采用了一套极其严苛的资源解耦逻辑。对于开发者来说,这意味着在构建多语言环境时,可以将翻译工作完全从业务逻辑中剥离。
- 动态加载机制:Telegram 客户端支持根据系统设置实时切换语言,不需要重启应用,这得益于其内部构建的内存映射字典。
- 占位符的高效注入:在处理动态文案时,Telegram 使用了基于索引的参数注入方式,这比基于字符串名称的检索速度更快,且避免了拼写错误带来的崩溃风险。
如果你正在开发一个面向多语言的 Bot,建议参考这一策略:使用 JSON 或 YAML 格式维护语言包,并在运行时通过 ID 索引而非字符串字面量进行调用。这种做法能显著降低维护难度,并提升在高并发场景下的处理效率。

服务端处理性能的极限优化
谈到 Telegram 多语言开发,必须提到其服务端的性能表现。Telegram 利用了基于事件驱动的服务器架构,使得处理不同语言环境下的文本搜索、索引变得极其轻量。即使在数千万用户同时发送包含不同语言的多媒体消息时,其后端依然能保持极低的内存占用。
这种高性能背后的秘诀在于:它在处理多语言数据时,会根据字符集的不同自动切换最优的压缩算法。对于中文这类包含大量重复词汇的语言,其压缩比率远高于纯英文内容,从而进一步降低了带宽消耗。
总结与行动建议
Telegram 实现高效多语言开发的核心,在于协议层面的严谨设计与业务逻辑的解耦。对于广大开发者而言,不必盲目模仿其庞大的底层系统,但可以借鉴其“资源与逻辑分离”的设计模式。
在接下来的开发中,请优先采用以 ID 为核心的翻译管理系统,并确保 API 调用时采用 UTF-8 编码的最佳实践。通过优化这些细节,你也能让自己的 Telegram 工具或 Bot 拥有媲美原生应用的响应速度。